

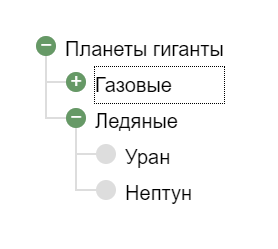
Древовидное представление (сворачиваемый список) можно сделать, используя только html и css, без использования JavaScript.
Древовидное представление (сворачиваемый список) можно сделать, используя только html и css, без использования JavaScript.
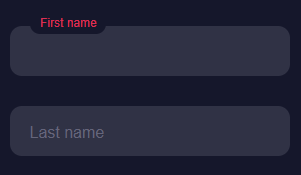
Рассматривается общий принцип реализации “прыгающих” подписей к полям формы – преобразования placeholder текстового поля в label снаружи него с помощью только CSS и HTML.

Вы можете использовать их для интерактивных компонентов с раскрыванием контента (accordion) совсем без JavaScript.
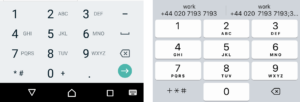
атрибут inputmode подсказывает, какой набор кнопок экранной клавиатуры предложить пользователю для удобства ввода в зависимости от типа input: none, numeric, tel, decimal, email, url, search

Как сделать поле ввода с автозаполнением (autocomplete, автокомплит) с применением только HTML. Элемент datalist.
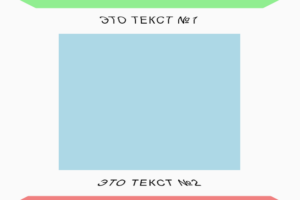
Экспериментальная техника 3D-макета для HTML-элементов со скроллом, заворачиванием и прочими возможностями.
Работа с узлами элементов (Element Nodes)
Добавление узлов. Использование текстовых узлов. Соединение и разделение текстовых узлов.
Динамический контент. Текстовые узлы (Text Nodes).
Типы узлов (Node Types). Атрибут, как узел Attribute. Атрибуты стилей.
Корень Документа (Document Root). Перемещение по Дереву Документа. Прямой доступ к элементам.
Уровни Объектной Модели Документа(DOM) и их поддержка в браузерах. Дерево документа (Document Tree). Узлы (Nodes).
